Over the last ten years, I worked with a lot of different database. I worked with traditional SQL databases such as DB2 and Oracle in a professional context. NoSQL databases such as DynamoDB have been my best friends during the last five years. On side projects I also touched stuff like MongoDB. However, I never worked with a graph-database up till now. Time to change that with Neo4J!
Graph Databases
Graph databases store information - as the name implies - as a graph.
They create a network between different nodes by defining relations.
This makes it easy to see how entities stand to each other.
Every relation has a semantic.
In a traditional SQL database, this would be implemented by JOIN operations which is usually complex and slow.
Note that there are two types of graph databases:
- RDF based graph databases which store everything as simple triplets
- Property Graphs (like Neo4J) which store information as nodes and edges with properties
(More here)
Example
Let’s make an example. Below you can see a dependency graph from the demo project I posted on GitHub.
- There are three shops (EDEKA, ATU and Media Markt)
- Each shop has a couple of locations
- Shops might have the same location (maybe they are in the same shopping-center)
- There are products which are sold by shops
- Products are compatible with each other or respectively require another product
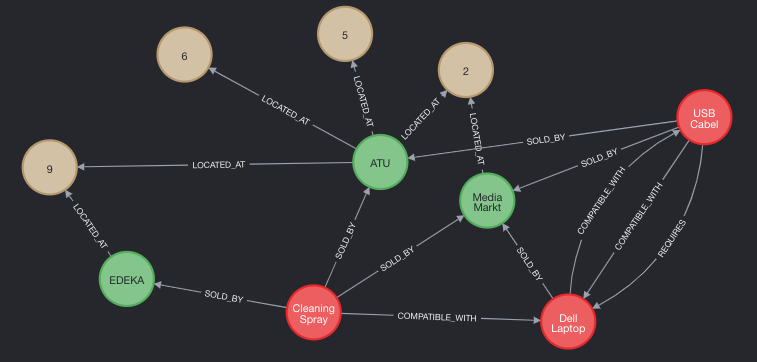
If we try to break down the data model, we will have the following:
- 3 entities (
shop,locationandproduct) - 4 relations (
located_at,sold_by,compatible_with,requires)
In a relational SQL database this would look like this:
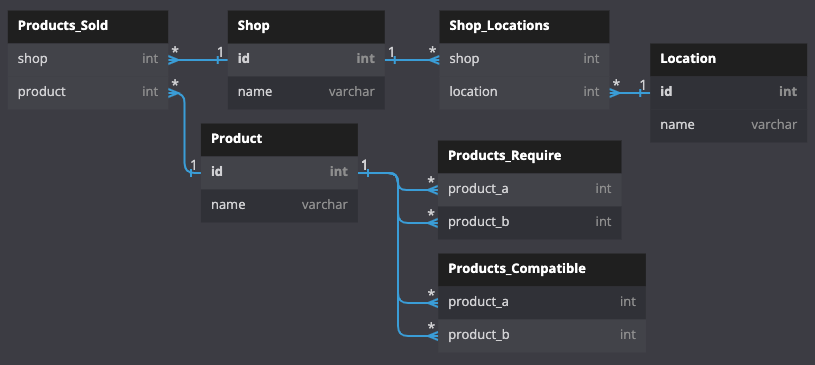
- 3 tables for the entities (
shop,locationandproduct) - 4 tables for the relations (many-to-many relationship)
The main difference between graph databases and relational databases is the following:
- Building relations in SQL is hard, but easy in Graph databases.
Relations in SQL means to use
JOINoperations which are complex and not efficient. - SQL databases focus on single tables with a strong schema and transaction handling. So while relation databases are super efficient with single entries, graph databases are efficient with relations.
So how does a JOIN operation look like in Neo4J?
MATCH (p:product)-[r:SOLD_BY]->(s:shop)
WHERE EXISTS {
MATCH (s)-[:LOCATED_AT]->(:location {city: 'Karlsruhe'})
}
RETURN p.name, s.name
This query selects all products which are sold in “Karlsruhe” (including the shop name). The result looks like this:
| p.name | s.name
+---------------------+----------
| "USB Cabel" | "ATU"
| "Cleaning Spray" | "ATU"
Neo4J with Spring Boot
I prepared a simple demo project which shows how to use Neo4J with Spring Boot. You can find the project on GitHub. It shows a simple example with some entities (see example above), REST-controllers and boilerplate-code.
- Define entities and relations
- Create data
- Query nodes and relations
More
- https://memgraph.com/blog/graph-database-vs-relational-database
- https://neo4j.com/developer/spring-data-neo4j
- https://www.baeldung.com/spring-data-neo4j-intro
- https://www.wisecube.ai/blog/knowledge-graphs-rdf-or-property-graphs-which-one-should-you-pick
Best regards, Thomas.